大模型,大,能力强,好用!
但单一大模型在算力、数据和能耗方面面临巨大的限制,且消耗大量资源。
而且目前最强大的模型大多为闭源,对AI开发的速度、安全性和公平性有所限制。

AI大模型的未来发展趋势,需要怎么在单一大模型和多个专门化小模型之间做平衡和选择?
针对如此现状,两位斯坦福校友创办的NEXA AI,提出了一种新的方法:
采用functional token整合了多个开源模型,每个模型都针对特定任务进行了优化。
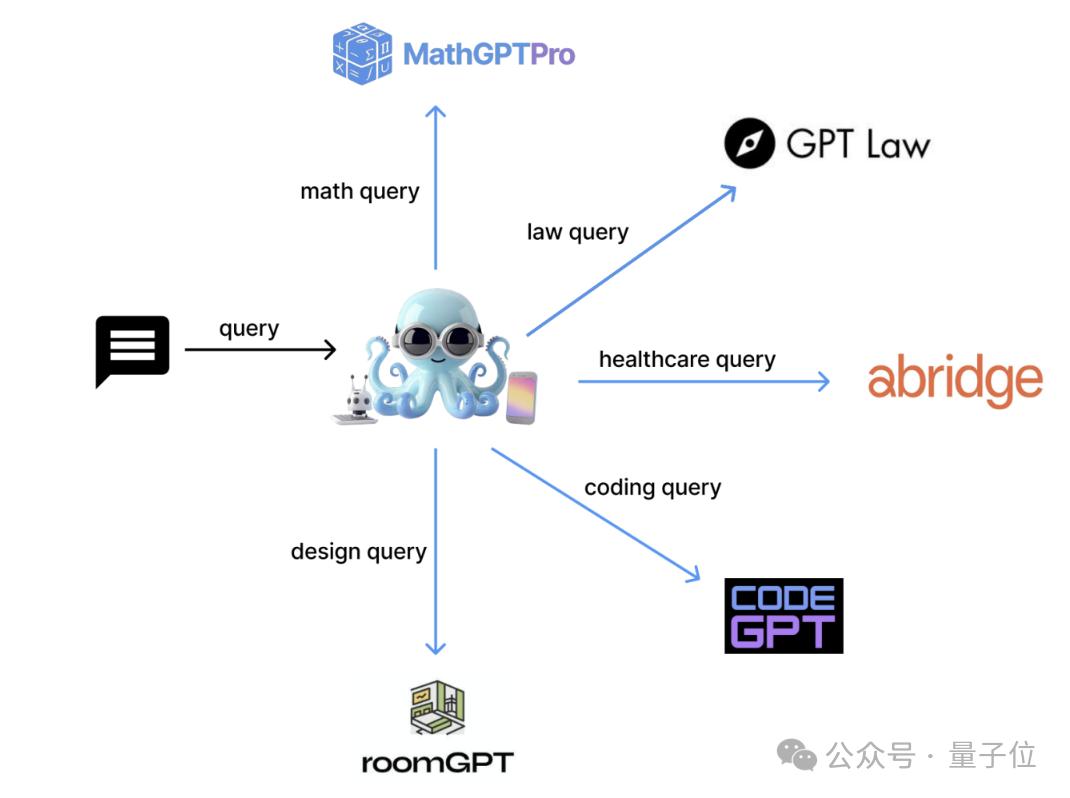
他们开发了一个名叫Octopus v4的模型,利用functional token智能地将用户查询引导至最合适的垂直模型,并重新格式化查询以实现最佳性能。
介绍一下,Octopus v4是前代系列模型的演化,擅长选择和参数理解与重组。
此外,团队还探索了使用图作为一种多功能数据结构,有效地协调多个开源模型,利用Octopus模型和functional token的能力。
通过激活约100亿参数的模型,Octopus v4在同级别模型中实现了74.8的SOTA MMLU分数。
Octopus系列模型
这里要重点介绍一下Octopus-V4-3B。
它拥有30亿参数,开源,是Nexa AI设想中的语言模型图的主节点。
该模型专为MMLU基准测试话题定制,能够高效地将用户查询转换成专业模型可以有效处理的格式。
它擅长将这些查询正确引导至相应的专业模型,确保精确且有效的查询处理。
Octopus-V4-3B具备以下特点:
紧凑尺寸:Octopus-V4-3B体积紧凑,使其能在智能设备上高效、迅速地运行。
准确性:利用functional token设计准确地将用户查询映射到专业模型,提高了其精度。
查询重格式化:帮助将自然人类语言转换为更专业的格式,改善了查询描述,从而获得更准确的响应。
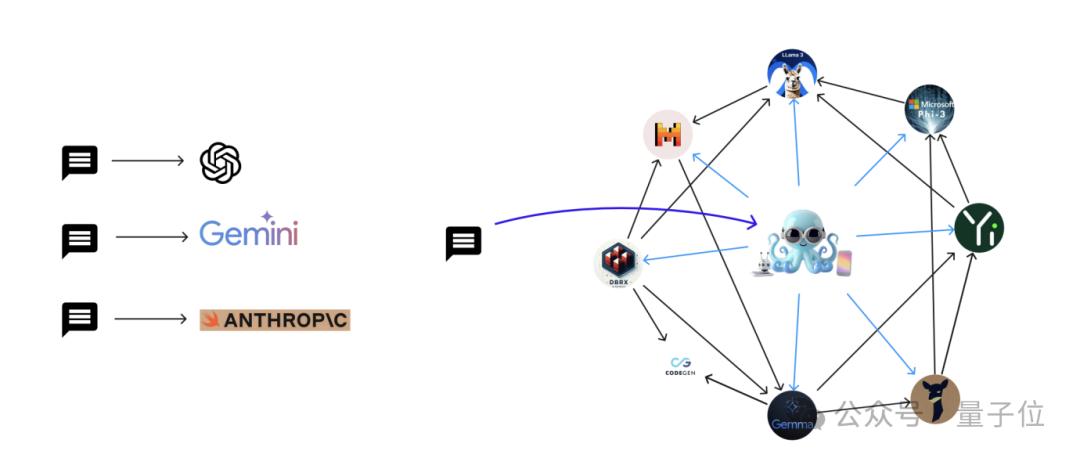
Nexa AI把语言模型作为图中的节点整合,并提供了针对实际应用定制的系统架构。
此外,讨论了使用合成数据集对Octopus模型进行训练的策略,强调了这种语言模型图在生产环境中的系统设计。
从Octopus v2提取的用于分类的语言模型
研究人员在Octopus v2论文中介绍了一种名为functional token的分类方法。
Octopus v2模型有效地处理了这一任务:

图中的语言模型作为节点
考虑一个定义为:G=(N,E)。
其中N代表图中的各种节点,E代表连接这些节点的边。
节点分为两种类型:
一,主节点Nm,它们通过将查询定向到合适的工作节点Nω并传递执行任务所需的信息来协调查询。
二,工作节点,接收来自主节点的信息并执行所需的任务,使用Octopus模型来促进进一步的协调。
节点信息传输过程如下图所示。
为了处理用户查询q并生成响应y,研究人员将概率建模为:
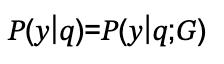
对于只涉及一个工作节点的单步任务,该过程可以定义为:
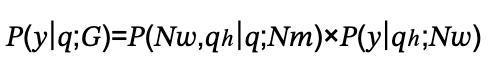
这里,P(Nω,ph|q;Nm)使用Octopus v2模型为
以上就是小编为大家介绍的杏宇官网:3B模型新SOTA,开源AI让日常调用不同大模型更简单的全部内容,如果大家还对相关的内容感兴趣,请持续关注山东杏宇环保设备有限公司
本文标题:杏宇官网:3B模型新SOTA,开源AI让日常调用不同大模型更简单 地址:http://www.guangda-graphite.com/news/hangye/841.html
- 上一篇:杏宇平台:日本车企,集体舞弊
- 上一篇:杏宇平台:日本车企,集体舞弊

 客服1
客服1