
新智元报道
编辑:乔杨
数据和算力,是AI大模型最重要的两把「铲子」。
算力方面,英伟达的不断创新和各家代工厂的产能提高,让世界各处的数据中心拔地而起,研究人员暂时不用担心计算资源。
然而,近些年来,数据成为愈发严峻的问题。
根据华尔街日报的报道,OpenAI在训练GPT-5时已经遇到了文本数据不足的问题,正在考虑使用Youtube公开视频转录出的文本。
关于「数据耗尽」这个问题,非营利研究机构Epoch AI在6月4日发布了一篇最新论文。
根据他们的预测,未来10年内,数据增长的速度无法支撑起大模型的扩展,LLM会在2028年耗尽互联网上的所有文本数据。

论文地址:https://arxiv.org/abs/2211.04325
目前这篇论文已被ICML 2024接收。著名的硅谷天才少年Alexandr Wang也转发了这篇论文,并附上了自己的一番见解。
他创办的Scale AI专门为AI模型提供训练数据,估值已经飙升到138亿,是当下硅谷最炙手可热的明星独角兽。
论文作者所属的机构Epoch AI则是一家非营利研究组织,成立于2022年4月,他们致力于调查人工智能的历史趋势,并帮助预测其未来发展。
虽然这个组织目前只有13名员工,且分布在世界各地,但他们的工作有非常广泛的影响。
英国和荷兰的政府报告都曾引用Epoch AI发表的论文。RAND智库的研究员表示,Epoch的AI模型数据库对于政策制定者来说是宝贵的资源,「世界上没有其他数据库如此详尽和严谨」。
预测方法
Epoch AI凭什么预测出2028年这个时间点?
说得直白一点,数据量就像一个水池。有存量、有增量,是否够用就要同时看供给侧和需求侧,预测AI模型的数据集会不会把水池抽干。
数据存量
首先需要估计目前互联网上的文本数据存量S。

定期更新的开源数据集Common Crawl爬取到了超过2500亿个网页,包含130T tokens。但这不是全部的网络内容,还需要统计索引网络的大小。
我们先假设谷歌搜索引擎包含了所有索引网站,可以使用「词频法」估计其中的页面数量。
比如,如果「chair」这个词出现在Common Crawl 0.2%的页面中,而且谷歌可以搜索到40B个包含「chair」的网页结果,就能初步预估出整个索引网络的大小约为40B/0.002=20T个页面。
采用这种方法,论文估算出谷歌索引包含约270B个页面,每个网页约有1.9KB纯文本数据,这表明整个索引网络的数据量大概为500T,是Common Crawl的5倍。
除此之外,还可以用另一种思路建模,估算整个互联网的数据总量——从使用人数入手。
网络上大部分文本数据都是用户生成的,并存储在各种平台上,因此,考虑互联网用户数和人均产生数据量,即可估计人类生成的公开文本数据量。
根据人口增长以及互联网逐渐普及的趋势,论文对互联网用户增长趋势进行建模,得出的曲线与历史数据非常吻合。
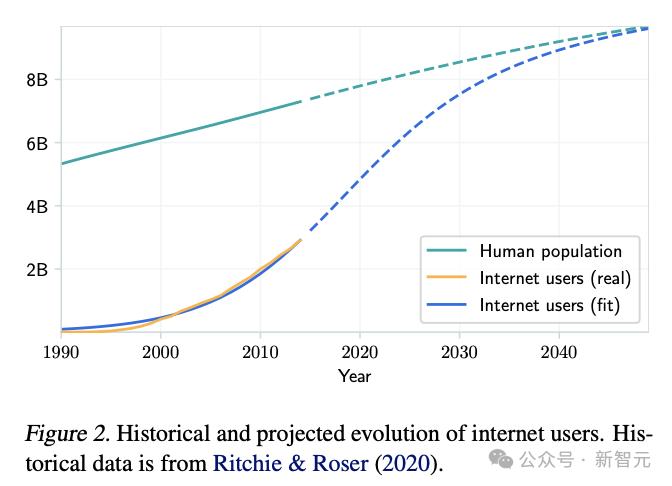
假设每个用户平均生成数据率保持不变,论文预计2024年上传的文本数据总量为180T~500T tokens。
根据这个预测结果以及已知的增长趋势,论文预估,互联网上的存量数据为3100T。
由于同时考虑了索引网络和深层网络(搜索引擎无法触及的网页),这个数字可以看作索引网络数据量的上限。
数据质量
5G时代的冲浪选手应该都有体会,虽然在同一个互联网,但文本和文本的质量可以有云泥之别。
比如,在书籍或维基百科的文本上训练出的模型,与Youtube评论喂出的模型,可能有很大的性能差异。因此,只用token数量衡量数据的话,就过于片面了。
但也不能对网络数据失去信心。之前有多项研究表明,通过仔细的过滤和数据处理,网络数据带来的性能依旧优于人工精心挑选的语料库。

论文地址:https://arxiv.org/abs/2306.01116
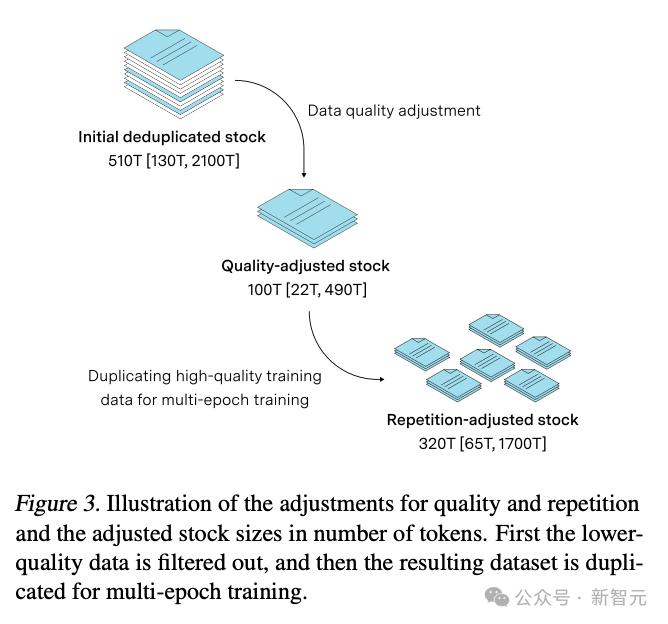
研究人员尝试对Common Crawl数据集进行类似的处理,发现过滤后数据集大小会降低30%。同时,另一项去年的研究也发现,剪除Common Crawl中50%的重复数据可以实现最佳性能。
因此,有比较充足的理由相信,数据总量的10%-30%可作为高质量数据用于训练,相当于索引网络510T数据中的100T左右。
数据集大小
以上是对互联网数据池的预估,是数据的供给方。接下来,需要对数据使用方——数据集容量(变量D)进行预估。
Epoch曾经在2022年发表了一个知名的机器学习模型数据库,包含了300多个模型,从中选取2010年-2024年间发表的80余个LLM进行分析。
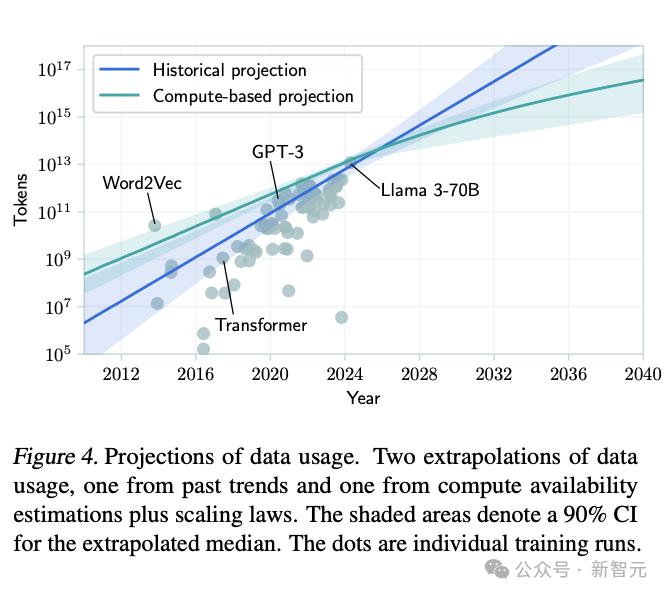
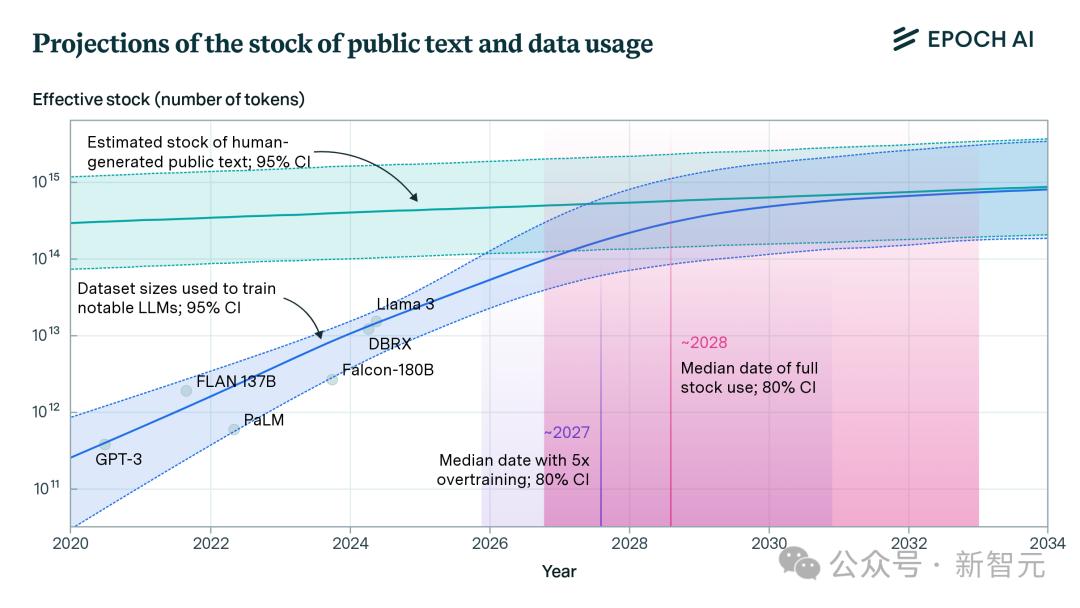
上图表明,目前LLM使用的最大训练集约为10T。Epoch AI之前也曾预估过,GPT-4训练集大小达到了12T tokens。
如果直接根据历史趋势进行外插(图中蓝线),那么到2030年,模型可以接受超过1000T tokens的训练。
但这个结果没有同时考虑算力的限制。根据Scaling Law,Transformer架构所需的数据量大致随训练算力的平方根扩展。
将计算资源和电力资源的约束引入后,就得到了下图中的预测曲线。
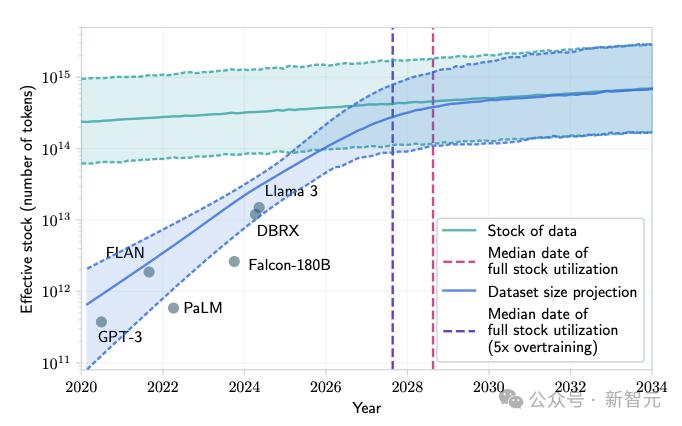
由此,论文就得出了预测结果。按照目前互联网数据总量和训练数据集的增长速度,如果以当前趋势继续下去,数据耗尽年份的中位数是2028年,最大可能性是2032年。
这意味着,未来10年内,数据将成为LLM的重大瓶颈,「数据墙」将成为现实。
慢着,记不记得之前我们预估过,整个互联网上的文本数据总量约为3100T,这些数据怎么没有算进去?
遗憾的是,这部分数据大多分布在Fackbook、Instagram、WhatsApp等社交媒体上,抓取过程不仅复杂、昂贵,而且涉及个人隐私相关的法律问题,因此几乎无法应用于LLM的训练。
但Meta公司等机构似乎没有放弃,仍在探索可能的路径来利用这些数据。
「数据墙」挡不住LLM?
这篇论文并没有止步于一个偏向于悲观的预测结论,因为同时考虑其他的因素,「数据墙」只会让模型扩展的速度放缓,而不是完全停滞。
Epoch AI的创始人也在此前的采访中表示过,虽然我们能看到「数据耗尽」的前景,但「目前还没有感到恐慌的理由。」
目前就至少有两种策略可以绕过人类文本数据的瓶颈,而且在论文作者看来,这两种方法都是「前途无量」。
AI生成数据
根据报道,仅OpenAI一家公司的模型每天就能生成100B个单词,也就是每年36.5T个单词,相当于Common Crawl中优质单词的总数。
这远远快于人类生成文本的速度,可以让数据存量急剧扩大,而且在模型输出相对容易验证的领域很有前景,比如数学、编程、游戏等等。
使用合成数据训练的最著名模型莫过于AlphaZero,它通过自我对弈达到了人类棋手都未能企及的水平。
此外2024年最新发布的AlphaGeometry同样使用合成数据进行训练,尝试解决几何问题。
然而,当合成数据推广到自然语言领域时,似乎存在一些本质问题。
之前有研究表明,使用模型输出的文本进行迭代训练,会丢失有关人类文本数据分布的信息,让生成的语言越来越同质化且不切实际。
有研究者还把合成数据导致的模型崩溃形象比喻为「近亲结婚」,称这种LLM为「哈布斯堡模型」。
但这个问题也并非无解。有之前的研究证明,通过使用多样的训练数据,或者混合一些人类文本数据,既可以合理利用训练数据,又能一定程度上缓解副作用。
多模态和迁移学习
另一种选择就是超越文本数据,从其他领域「掘金」。
除了我们熟知的视频、图像之外,金融市场数据或科学数据库也可以使用。有人预测,到2025年,基因组学数据将以每年200-4000万兆字节的速度增长。
除了这两种方法,很多实验室和初创公司也正在积极探索。比如DatologyAI正在研究一种名为「课程学习」(curriculum learning)的方法,把数据按特定顺序输入,以期LLM能够在概念之间形成更智能的联系。
2022年他们发表的论文显示,如果数据无误,使用这种训练方法的模型可以用一半的数据实现相同的效果。
也许,Epoch AI创始人的话的确有道理。虽然数据是有限的,「数据墙」也是可预期的,但方法总比困难多。
「最大的不确定性在于,你会看到什么样的技术突破。」
参考资料:
https://x.com/EpochAIResearch/status/1798742418763981241
https://epochai.org/blog/will-we-run-out-of-data-limits-of-llm-scaling-based-on-human-generated-data
https://x.com/alexandr_wang/status/1799930063192002701
https://time.com/6985850/jaime-sevilla-epoch-ai/
以上就是小编为大家介绍的杏宇登入:Scaling Law触礁「数据墙」?Epoch AI发文预测LLM到2028年耗尽所有的全部内容,如果大家还对相关的内容感兴趣,请持续关注山东杏宇环保设备有限公司
本文标题:杏宇登入:Scaling Law触礁「数据墙」?Epoch AI发文预测LLM到2028年耗尽所有 地址:http://www.guangda-graphite.com/news/gongsi/984.html

 客服1
客服1